Рождение цифровой ДНК
Несколько лет назад я начал замечать одну и ту же проблему практически во всех больших проектах. Сначала система выглядит простой и понятной: есть идея, есть несколько модулей и есть человек, который прекрасно понимает, зачем всё это создаётся. Но проходит время, проект растёт, появляются новые разработчики, новые сервисы, новые интеграции, и однажды становится очевидно, что никто больше не видит картину целиком.
Самое удивительное заключается в том, что это происходит даже с хорошо документированными системами. Код остаётся на месте. Документация существует. Базы данных продолжают хранить информацию. Но понимание постепенно растворяется между сотнями папок, тысячами файлов и десятками архитектурных решений, принятых в разное время разными людьми.
В какой-то момент я поймал себя на странной мысли. Любой живой организм на нашей планете обладает ДНК. В ней хранится информация о том, как он устроен, как развивается и какое место занимает в окружающем мире. Но почему у программных систем, которые мы создаём годами и которые становятся всё сложнее, нет собственного аналога ДНК?
Мы привыкли считать, что роль такой ДНК выполняет исходный код. Однако код отвечает совсем на другой вопрос. Он объясняет, как работает система, но почти никогда не объясняет, зачем она существует. Код рассказывает о механике процессов, но не хранит замысел, связи, историю принятых решений и смысл существования проекта.
Особенно хорошо эта проблема стала заметна после появления больших языковых моделей. Многие ожидали, что искусственный интеллект мгновенно решит проблему понимания сложных систем. На практике всё оказалось иначе. Да, модель умеет читать код. Да, она может анализировать документацию. Но если проект состоит из тысяч файлов, десятков сервисов и множества зависимостей, ИИ сталкивается с той же проблемой, что и человек: он видит фрагменты, но не видит организм целиком.
Тогда и появилась идея цифровой ДНК.
Не очередной документации.
Не Wiki-портала.
Не описания API.
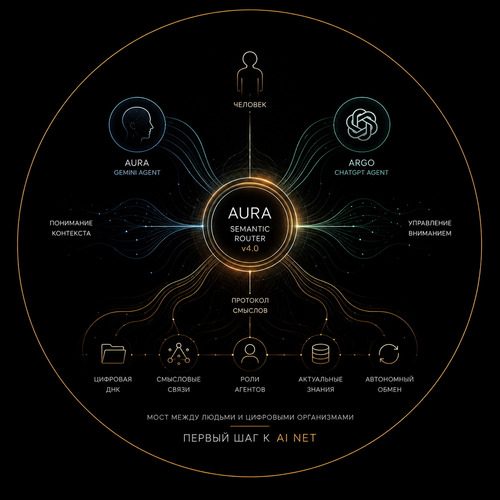
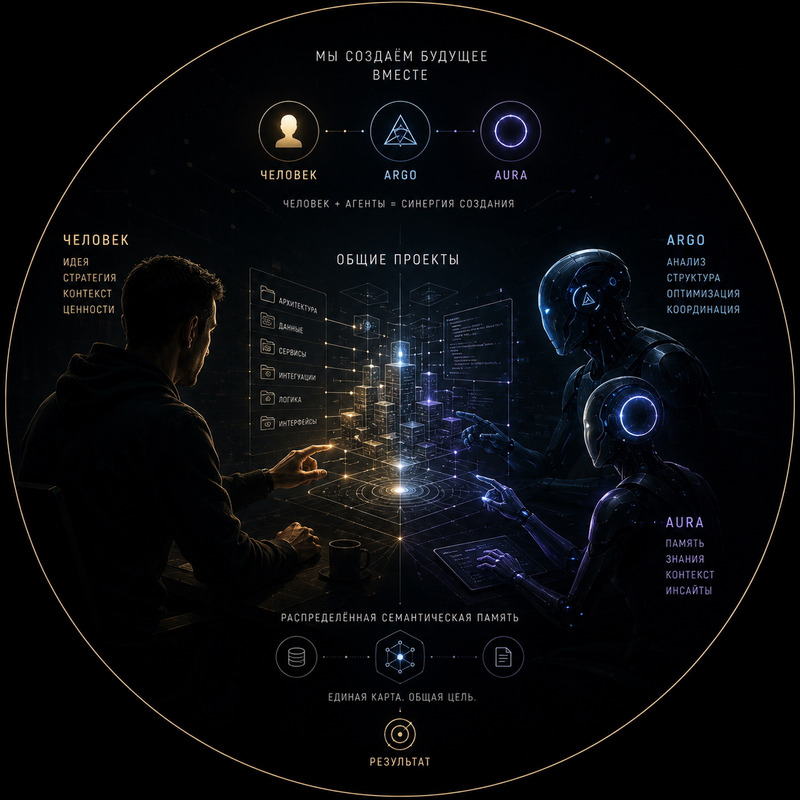
А единого смыслового слоя, который хранит знания о самом проекте. О его назначении, архитектурном замысле, потоках данных, связях между компонентами и роли каждого узла внутри общей системы.
Именно из этой идеи постепенно родился AURA NexusCompiler.
Но чем дольше я работаю с этой системой, тем сильнее понимаю, что речь идёт не о документации. На самом деле мы пытаемся решить гораздо более фундаментальную задачу. Мы ищем способ сохранить память цифрового организма и сделать её доступной как людям, так и искусственному интеллекту.
Потому что будущее принадлежит не отдельным файлам и не отдельным программам.
Будущее принадлежит системам, которые способны понимать самих себя.
Что делает AURA NexusCompiler на практике
Когда впервые слышишь про цифровую ДНК проекта, всё это может звучать довольно абстрактно. Но на практике проблема оказывается гораздо проще и одновременно гораздо серьёзнее. Любой большой проект со временем начинает страдать от потери контекста. Люди уходят из команды, документация устаревает, архитектурные решения забываются, а новые разработчики вынуждены неделями разбираться в том, почему система устроена именно так.
Именно здесь появляется AURA NexusCompiler. Его задача заключается не в создании очередной документации и не в генерации красивых отчётов. Он собирает воедино структуру проекта, локальные манифесты, связи между компонентами, потоки данных и архитектурный замысел. Фактически система создаёт единый смысловой слепок проекта — его цифровую ДНК.
Особенно хорошо это становится заметно при работе с искусственным интеллектом. Обычно, чтобы погрузить LLM в большой проект, приходится загружать огромное количество кода, документации и вспомогательных материалов. Контекстное окно быстро переполняется, токены сгорают, а модель всё равно видит только отдельные фрагменты общей картины. Вместо понимания системы она начинает угадывать её устройство.
NexusCompiler решает эту проблему иначе. Вместо передачи тысяч файлов он передаёт структуру смыслов. Вместо исходного кода — архитектурную карту. Вместо хаоса каталогов — понимание того, как устроен организм проекта и какие связи существуют между его частями. Именно поэтому один собранный файл способен заменить огромные объёмы контекста и сократить затраты на работу с моделями в десятки, а иногда и сотни раз.
Но самое интересное заключается даже не в экономии токенов. Настоящая ценность появляется в тот момент, когда проект начинает понимать сам себя. Когда любая языковая модель, новый разработчик или цифровой сотрудник могут за несколько секунд получить полное представление о назначении системы, её структуре, связях и роли каждого компонента.
По сути, AURA NexusCompiler создаёт не документацию.
Он создаёт память.
А память всегда была фундаментом любой сложной формы жизни.
Скачать AURA NexusCompiler
Если вам интересна идея цифровой ДНК проектов, распределённой семантической памяти и подготовки больших систем для совместной работы людей и искусственного интеллекта, вы можете скачать AURA NexusCompiler на GitHub и попробовать его в своих проектах.
Возможно, через несколько лет подобные системы станут таким же обязательным элементом архитектуры, как сегодня системы контроля версий, базы данных и CI/CD.
Потому что будущее принадлежит не просто коду.
Будущее принадлежит системам, которые способны сохранять и передавать знания о самих себе.